.svg)
How Agentic AI is Rewriting the Rules of Flow Cytometry: An approach towards Automated Gating in AML.

May 19, 2026

Flow cytometry is one of the most powerful tools in modern biology. By suspending cells in a stream of fluid and passing them through a laser beam, we can simultaneously analyze multiple physical and chemical characteristics of millions of single cells. In complex oncology indications like Acute Myeloid Leukemia (AML), this technology is our primary lens into the bone marrow, allowing us to identify rare malignant blasts hidden within a chaotic cellular environment. It is as much an art as it is a science.
But flow cytometric data analysis also has a massive bottleneck. It's analysis remains intensely manual, subjective, and difficult to scale.
For decades, the gold standard for flow cytometry analysis has been manual gating. Highly trained immunologists spend hours staring at computer screens, drawing geometric polygons around clusters of dots on 2D biaxial scatter plots. They gate out non-cellular debris, exclude doublets (two cells stuck together), isolate live leukocytes, and drill down into highly specific phenotypic sub-populations.
In the context of Minimal Residual Disease (MRD) monitoring, where finding a single leukemic cell among 10,000 healthy cells changes a patient's treatment trajectory, the stakes for these manual gates are incredibly high. Yet, this process is fundamentally operator-dependent. Two scientists might look at the same CD45 vs. SSC scatter plot and draw slightly different gates. When you scale this across hundreds of samples, multiple instruments and different laboratories, this subjectivity creates massive bottlenecks and irreproducible data.
The industry needs a reliable approach to automated gating. At Elucidata, our recent work of analyzing over 150 flow cytometry files, averaging over 355,000 events per sample has laid the foundation of why early-generation AI failed to solve this, and how a new unsupervised approach is finally breaking the bottleneck.
Flow cytometry data is very noisy. When dealing with primary AML bone marrow samples, you aren't just looking for clean cell populations. There’s a massive data variability like instrument calibration differences, signal overlap, dead cells, doublets, and severe batch effects across different labs. Same markers do not always mean the same data behavior.
As a first step in this project, we established a solid foundation of data quality rather than designing complex neural networks to dump on the data. We built a robust preprocessing workflow to evaluate intrinsic dataset quality and contextual heterogeneity. Before any biological gating occurs, our pipeline autonomously scrubs the data. It corrects for time-based acquisition drift, dynamically filters out non-cellular debris and doublets, and normalizes fluorescence intensities across different cytometers.
But once you have clean data, how do you automate the discovery of malignant AML populations without relying on rigid, human-drawn templates?
The industry has been trying to automate flow cytometry for a decade, moving through distinct generations of technology:
To establish a baseline, our team trained a supervised XGBoost model to perform initial Quality Control (QC) gating, separating debris, doublets, dead cells, and live leukocytes. Tested on a rigorous sample split, the XGBoost model achieved a remarkable mean F1-score of 0.911 for identifying live leukocytes.
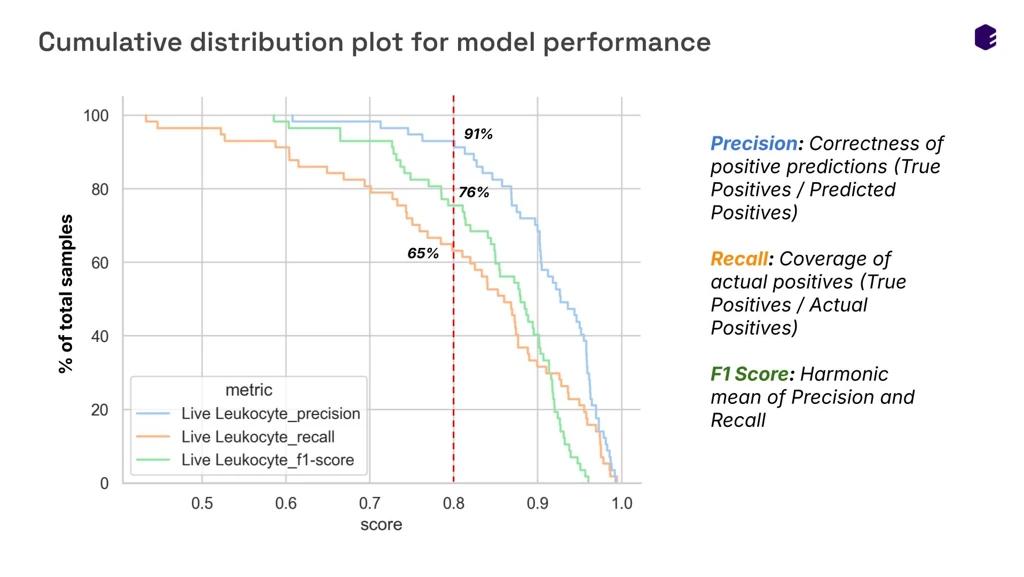
However, supervised models still require massive amounts of perfectly labeled ground-truth data, which is nearly impossible to acquire across highly heterogeneous, multi-panel AML cohorts. To truly automate gating across unseen biological contexts, we had to move beyond supervised constraints.
In clinical flow cytometry, a model that fails silently shouldn’t be considered at all. You cannot use a "black box" to make decisions about deadly diseases like leukemia.
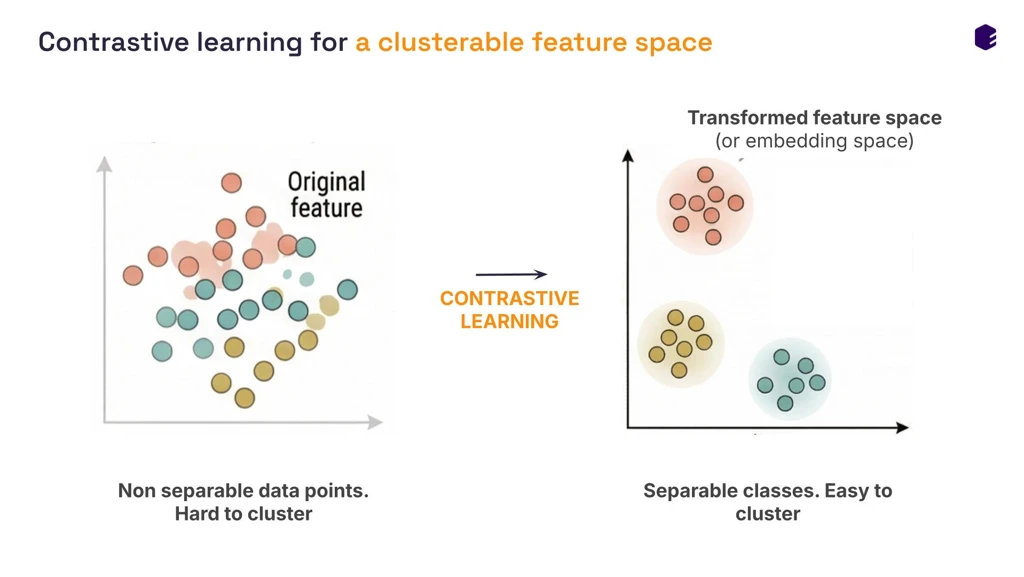
To solve this, we are shifting from purely supervised machine learning to unsupervised contrastive learning.
Supervised learning requires massive amounts of perfectly labeled data, which is nearly impossible to acquire across heterogeneous AML cohorts. Unsupervised contrastive learning flips the script. Instead of telling the AI what a "live blast cell" looks like, we let the model learn the fundamental architecture of the data itself.
Here is how it works:
The result is breathtaking. Without a single human drawing a manual gate or applying explicit labels, the raw 31-parameter flow data naturally separates into distinct, biologically meaningful phenotypic islands. Debris, doublets, healthy leukocytes, and malignant blasts cluster autonomously, completely robust to technical variation and donor-to-donor shifts.
To interpret these clusters, we developed a hierarchical, rule-based profiling strategy using optimized Z-score thresholds. By analyzing the expression relative to the specific sample's distribution, the algorithm autonomously labels the clusters:
This unsupervised approach successfully improved the mean F1-score for identifying live leukocytes to 0.851 across all tested samples, proving that AI can accurately isolate usable cells without relying on rigid, pre-labeled training sets.
Contrastive learning sets the stage for what we call Gen 3: Agentic Systems.
An agentic system doesn't just classify data, it reasons about it. By combining these highly robust, unsupervised embeddings with an intelligent multi-agent framework, we are building a system that acts like a seasoned immunologist. This is the foundation of Agentic AI in flow cytometry.
When our system encounters an out-of-distribution cell population in a new AML sample, it doesn't force it into a predefined box or fail silently. It uses biological context to reason about the unexpected finding. . It can look at a distinct cluster, analyze its marker expression patterns, and logically deduce its identity by explaining every gating decision with verifiable evidence. This also lays foundation for our framework towards the Turing Test for Drug Discovery.
Automating flow cytometry isn't about replacing the scientist, it is about liberating them from the biaxial plot. By ensuring that biomedical data is truly AI-ready, and deploying agentic systems that adapt and explain, we are bringing a new level of precision and scalability to AML research and beyond.

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



