
Fully automated, High-Accuracy data extraction for complex fields from any publication.

Launch 1000s of parallel extraction jobs at once. Built for enterprise-scale document extraction & metadata enrichment.

Compared to human counterparts Polly Xtract can extract highly accurate data from publication in as low as 1 second


Leverage Polly’s LLM-powered system to auto-generate the optimal metadata schema directly from the content of your documents, no restrictive templates required.

Define exactly which fields matter. Create or import your own ontologies, schemas, or data models for unmatched flexibility and control over what gets extracted.

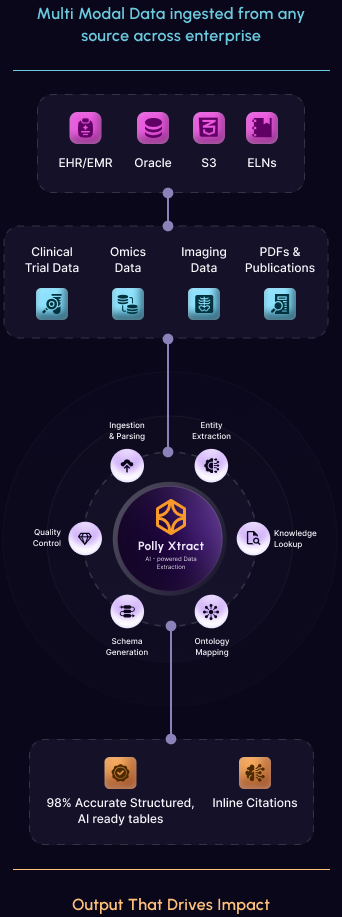
Extract structured data from PDFs, scanned images, Word documents, spreadsheets, and even audio recordings. Polly is source- and modality-agnostic, adapting to your workflow.

For complex or inferred data fields, Polly provides human-readable explanations showing how answers were derived, giving you confidence in every result.
Watch how our AI-powered tool effortlessly transforms dense clinical trial documents into clear, structured schemas. Whether you’re managing study design, regulatory submissions, or data integration, this demo shows how you can save hours of manual effort.
.webp)
.svg)
.webp)
.svg)


.webp)

.webp)
.svg)
.svg)
.webp)

.webp)


Polly Xtract is an advanced, proprietary AI-driven capability developed by Elucidata. It's designed to intelligently extract and structure complex data from a wide array of unstructured and semi-structured sources, including PDFs, images, free text, diverse tables, and combinations thereof.
While not a standalone product for purchase, Polly Xtract serves as a core technological engine that empowers our expert team to deliver unparalleled data curation services. It significantly enhances our ability to process vast quantities of heterogeneous research and operational data – from publications and EMR tables to increasingly complex domains such as chemical structures and regulatory filings. By automating and accelerating the critical first steps of data preparation, Polly Xtract enables us to undertake larger, more ambitious data projects for our clients with greater speed, accuracy, and efficiency, all while maintaining the highest standards of data quality. It represents Elucidata's commitment to leveraging cutting-edge technology to transform complex data into actionable insights for the biopharma and related industries
Polly Xtract follows a modular, multi-agent framework:
While generic LLMs (e.g., GPT-4) can parse documents, Polly Xtract is purpose-built for biomedical metadata curation:
Polly Xtract delivers high-accuracy, schema-aware metadata extraction from unstructured biomedical sources. Across 50+ metadata fields spanning study design, trial arms, and outcomes, it achieves:
In multiple cases, Polly Xtract outperformed manual curation - correctly extracting values absent in the ground truth but verifiable from the source. This contributed to a 4× increase in throughput, matching the monthly output of a 3-person expert team. Xtract also preserves explainability, with structured reasoning logs and field-level evidence.
Polly Xtract is best suited for organizations that manage high volumes of biomedical documents and require domain-specific accuracy. Target users include:
If required, our team can add the following customizations for cell-type annotation
Xtract is schema-flexible, supporting both pre-defined and user-defined metadata fieldsets.
Polly Xtract supports extraction across 23+ fields (as per preprint), including:
It handles both raw entity extraction and ontology-based normalization (e.g., “AML” → DOID:9119).
The pipeline supports cross-document and multimodal parsing. Agents are designed to:
Polly Xtract is not yet a standalone commercial product. However, it is actively used within Elucidata's curation operations and is available for early-access partnerships and also enterprise deployments. Teams working on high-volume biomedical data extraction are invited to reach out for collaboration discussions.
.svg)

.svg)



.svg)
%201%20(1).svg)
%20(1).svg)
%201%20(1).svg)
.svg)

.png)




