.svg)
Polly Scout: Find the Fastest Path to Right Public Biomedical Data

February 25, 2026

Manual dataset auditing is one of the biggest hidden bottlenecks in drug discovery. Polly Scout replaces weeks of painstaking effort with AI-driven precision delivering audit-ready results in under an hour.
Ask any computational biologist or data scientist working in drug discovery about the early stages of a new project, and you'll hear a familiar story: before a single model trains or a single hypothesis is tested, there are days sometimes weeks of manual searching, downloading, reviewing, and rejecting datasets.
This isn't a niche problem. Across R&D organizations, teams spend between 5 and 25 days per project just auditing public data sources. The work is repetitive, error-prone, and entirely disconnected from the high-value scientific thinking these experts were hired to do.
The biomedical data landscape is fragmented by design. Repositories like GEO, ArrayExpress, and PMC each have their own schemas, ontologies, and submission standards. Navigating them at scale especially when you're trying to find datasets relevant to a rare indication or a highly specific cellular context is a genuine technical challenge.
Polly Scout is Elucidata's AI-driven accelerator purpose-built for this exact problem. Rather than replacing scientists, it removes the grunt work that precedes their best thinking. Using a suite of task-specific LLM agents, Scout automates the entire data discovery and auditing pipeline from requirements intake to ranked, review-ready dataset shortlists.
The system operates against a continuously updated corpus of over 800,000 studies and more than 7 million articles, with metadata mapped to established biomedical ontologies including NCBI Taxonomy, BTO, and MONDO.
Here's how the workflow unfolds:
One of Scout's most operationally useful features is its transparent tiering system. Rather than returning an undifferentiated list of hundreds of "relevant" datasets, Scout categorizes results into three clear priority levels:
Subject matter experts skip the initial sorting entirely and engage only with datasets that have already been evaluated, spending their attention where it matters most.
Elucidata ran Polly Scout against one of the more demanding real-world use cases: auditing a large corpus for complex disease indications including head and neck squamous cell carcinoma (HNSCC) and pancreatic ductal adenocarcinoma (PDAC).
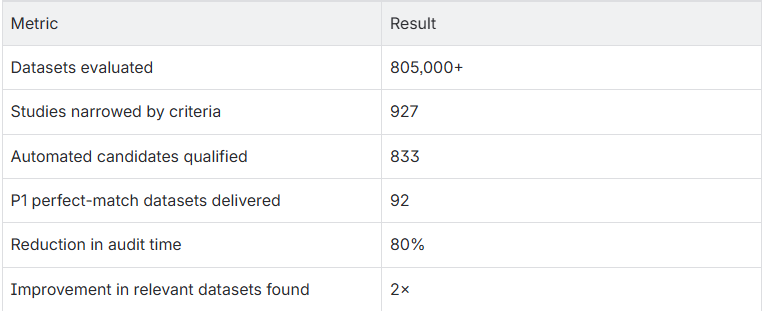
Two results stand out here. First, the 80% reduction in audit time is significant, but the second finding is arguably more important: Scout surfaced twice as many relevant datasets compared to manual methods. Human reviewers working under time pressure are prone to anchoring on familiar sources and missing long-tail datasets that might represent exactly the experimental condition they need. Scout doesn't tire, doesn't anchor, and doesn't skip.
The operational implications extend well beyond time savings. When your SMEs are no longer spending three weeks on data audits, several things become possible that weren't before.
Projects that were deprioritized due to data sourcing complexity become viable. Client requests that previously required long lead times can be turned around in days. Foundation models and downstream analyses start from a richer, more accurately scoped data foundation which has measurable downstream effects on model quality and reproducibility.
There's also a cost dimension. Manual curation at scale requires either large teams or long timelines. Polly Scout compresses both, allowing organizations to expand their data infrastructure without proportionally expanding headcount.
The biomedical data challenge isn't going to simplify on its own. As the number of publicly available studies continues to grow and the complexity of multi-modal, multi-indication projects increases, the gap between what teams need and what manual methods can deliver will only widen.
Polly Scout represents a structural solution to a structural problem: replacing a bottleneck that has been accepted as a cost of doing science with an automated, high-accuracy pipeline that makes data discovery a competitive advantage rather than a liability.
If your team is still allocating weeks of SME time to data auditing, that's not a workflow problem. It's an infrastructure gap and one that's now entirely addressable.
Connect with us to establish a discovery-ready data infrastructure and move from raw data to analysis-ready insights in a fraction of the time.

.svg)
.svg)


%201%20(1).svg)















.svg)
%20(1).svg)



