.svg)
Polly Co-Scientist: A Multi-Agent AI System for Scientific Workflows
Swastik Gowda L

March 18, 2026

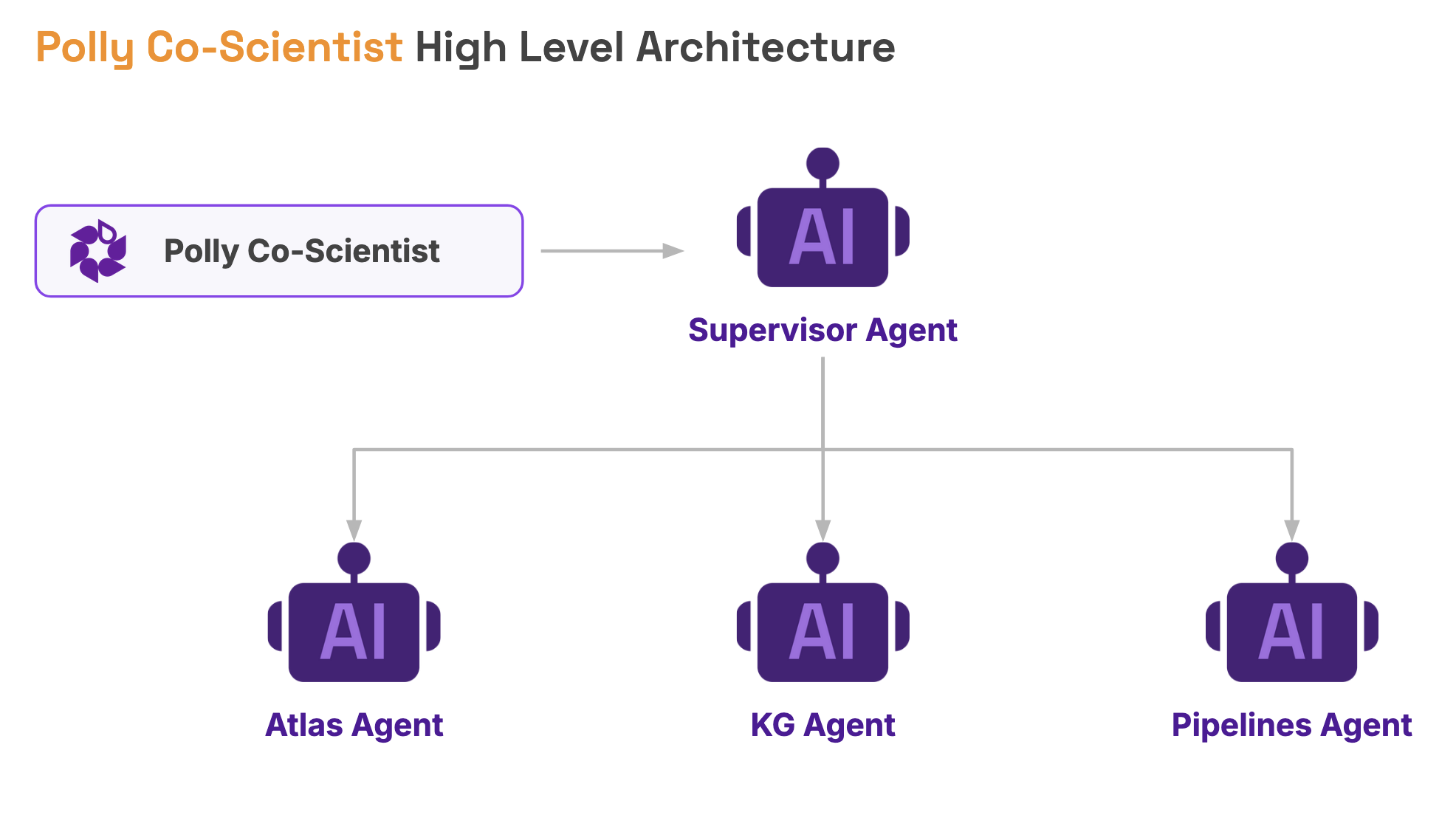
In Polly, we have multiple services like Polly Pipelines, Atlas, and Knowledge Graphs. We wanted a single chat interface through which a user could communicate with all these services. So this was the requirement: a unified, intelligent chat interface that can seamlessly communicate with different services. This led us to build a multi-agent communication system.
What we thought of was building a hierarchical system where our chat system internally has a supervisor agent that communicates with different specialized agents. When we say specialized agent, we mean each individual agent that specializes in one service. For example, we built a KG agent (Knowledge Graph agent), an Atlas agent that specializes in Atlas services, and a Pipeline agent for pipelines.
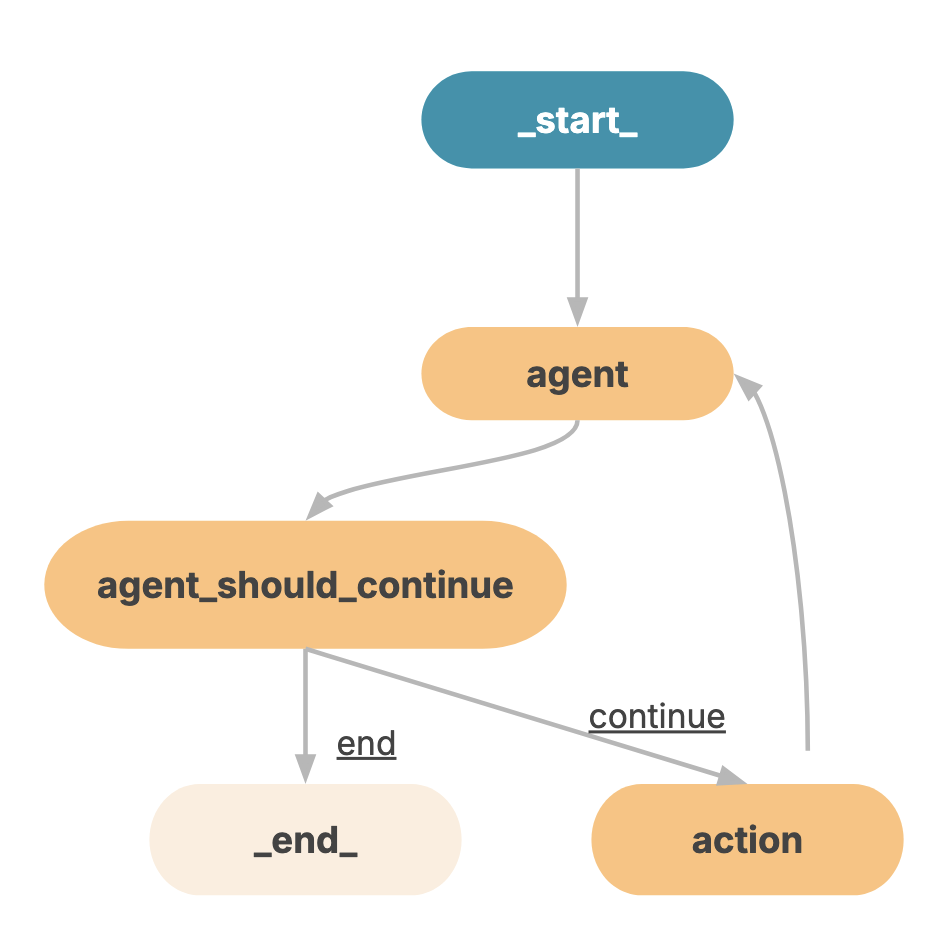
Now, before we dive deep into it, it is important to understand what an agent is. It is the simplest unit here. The anatomy of an agent mainly contains three things:
.png)
These components are usually combined using agentic frameworks which help glue everything together.
We chose LangGraph as our agentic framework. Before finalizing it, we evaluated various frameworks available in the industry, such as LangGraph, Pydantic AI, CrewAI, etc. We did POC with these frameworks, and after that, we felt LangGraph was the right choice for us because it has been around for some time, provides rich out-of-the-box features, is flexible, and is widely used, making it reasonably battle-tested.

To create such a hierarchical system, traditionally, a graph-based structure was used. The problem with these traditional systems was that they required significant manual effort, had rigid structures, and lacked intelligence. Each node had to be explicitly coded, making the system harder to scale and evolve.
We chose to approach this differently. The turning point was the improvement in LLM capabilities over the last few years. Models like GPT and Claude have become very strong at reasoning and decision-making. They can now understand user prompts, interpret them, decompose them, and route them to the correct specialized agent. This level of intelligent routing was not realistically possible earlier.
LangGraph provides something called a supervisor agent, and when combined with the latest GPT models, it showed promising results. It was able to reason well, route intelligently, and integrate seamlessly with specialized agents while providing a rich set of features.
When we actually implemented this system (chat → supervisor → specialized agents → supervisor → user), we encountered a few challenges.
1. Information inconsistency. Sometimes, even after explicitly mentioning in the system prompt not to omit information, the supervisor agent would occasionally drop information coming from specialized agents. We were able to improve this to some extent through system prompt refinement.
2. Format alterations. Since multiple agents are involved, format consistency becomes important. Sometimes agents did not strictly follow the expected format. We improved this by tightening prompts and enforcing stricter formatting expectations so responses matched what the frontend expected.
3. Slow response time. Since multiple LLM operations are involved (user → supervisor → specialized agent → supervisor → user), these multiple hops increased latency.
4. Handle conversation history: LangGraph checkpointers helped us manage this. They act as connectors between the agent and PostgreSQL. The conversations are stored in PostgreSQL while LangGraph manages the conversational state.
For monitoring and debugging, we used LangSmith, which worked well for tracing and observing agent behavior.
From an infrastructure standpoint, we decided early that the system needed to be low-maintenance, extensible, and operationally efficient. We wanted to avoid architectures that required heavy ongoing management. After evaluating traditional server-based approaches versus serverless patterns, we chose an event-driven, serverless architecture because it provided built-in scalability with significantly lower operational overhead.
Our architecture consisted of:
We designed the system as an event-driven workflow, where prompts move through a queue into compute workers for processing. Since we already operate multiple services and anticipate adding more, we standardized how agents are built and integrated. We established a single monorepo for all agent code and defined a common structure that developers must follow when creating new agents. Clear documentation was also created so developers could quickly build and integrate new agents without friction.
To further simplify development, we built shared infrastructure utilities so agent developers could focus on domain logic rather than platform concerns. These shared capabilities included:
This significantly reduced development overhead and improved consistency across agents.
Another important challenge was handling long-running workflows. For example, when users submit computational pipelines, results may not be immediately available. To support this, we designed an asynchronous event feedback mechanism where delayed system events are captured and routed back into the user conversation, allowing users to receive updates as processing progresses.
After deploying the platform to production, the system performed well overall, though we did encounter several practical challenges. One of the most heavily utilized components was the Knowledge Graph (KG) agent, which exposed important scaling and design learnings. The next section covers those insights.
Knowledge Graph (KG) agents allow users to query complex graph data using natural language. However, building a reliable KG agent requires solving challenges around intent understanding, entity normalization, query generation, and result processing.
The first step in a KG agent pipeline is understanding the user’s query. The agent first identifies whether the query requires query execution, summarization, or general explanation, since not every question requires a database query.
It then maps the intent to the graph schema by identifying relevant node types, relationships, and properties so that the generated query uses the correct schema structure.
The agent also extracts entities from the question. These may include gene names, diseases, proteins, cohorts, or biological processes. However, user-provided entities often do not exactly match graph identifiers, which introduces another challenge.
To solve this, the agent performs entity normalization using strategies such as:
Candidate entities are then ranked to select the best match.
Once entities and schema mappings are identified, the agent constructs an execution plan describing the graph traversal strategy, node types, relationship directions, and filters. Based on this, the Cypher query is generated. Optionally, this plan can also be shown to users before execution for transparency.
Once finalized, the query is executed against the knowledge graph. This typically involves executing the query, polling status, retrieving results, and then processing and summarizing them into a human-readable response.
Query failures are inevitable due to incorrect schema assumptions, relationship direction errors, or Cypher syntax issues. To address this, we implemented automatic query repair. If execution fails, the system analyzes the error, corrects the query internally, and retries execution. The failure reason can also be reported for transparency.
Some areas we plan to improve include:
.png)

.png)


.svg)
.svg)


%201%20(1).svg)










.svg)
%20(1).svg)



