.svg)
Accelerate PK/PD-Driven Trial Design: Turn Unstructured Data into Actionable R&D Insights

April 8, 2026
Pharmacokinetic/Pharmacodynamic (PK/PD) modeling is the critical thread that connects early-stage drug discovery to late-stage clinical success. For R&D leaders, clinical scientists, and data teams, robust PK/PD data informs every major decision - from selecting the right dose in preclinical toxicology studies to evaluating target engagement in human trials.
However, there is a massive gap in how this data is consumed: the most vital information is buried inside unstructured, disjointed formats across peer-reviewed literature, supplementary files, and conference posters. Highly skilled scientists spend weeks manually curating data rather than analyzing it.
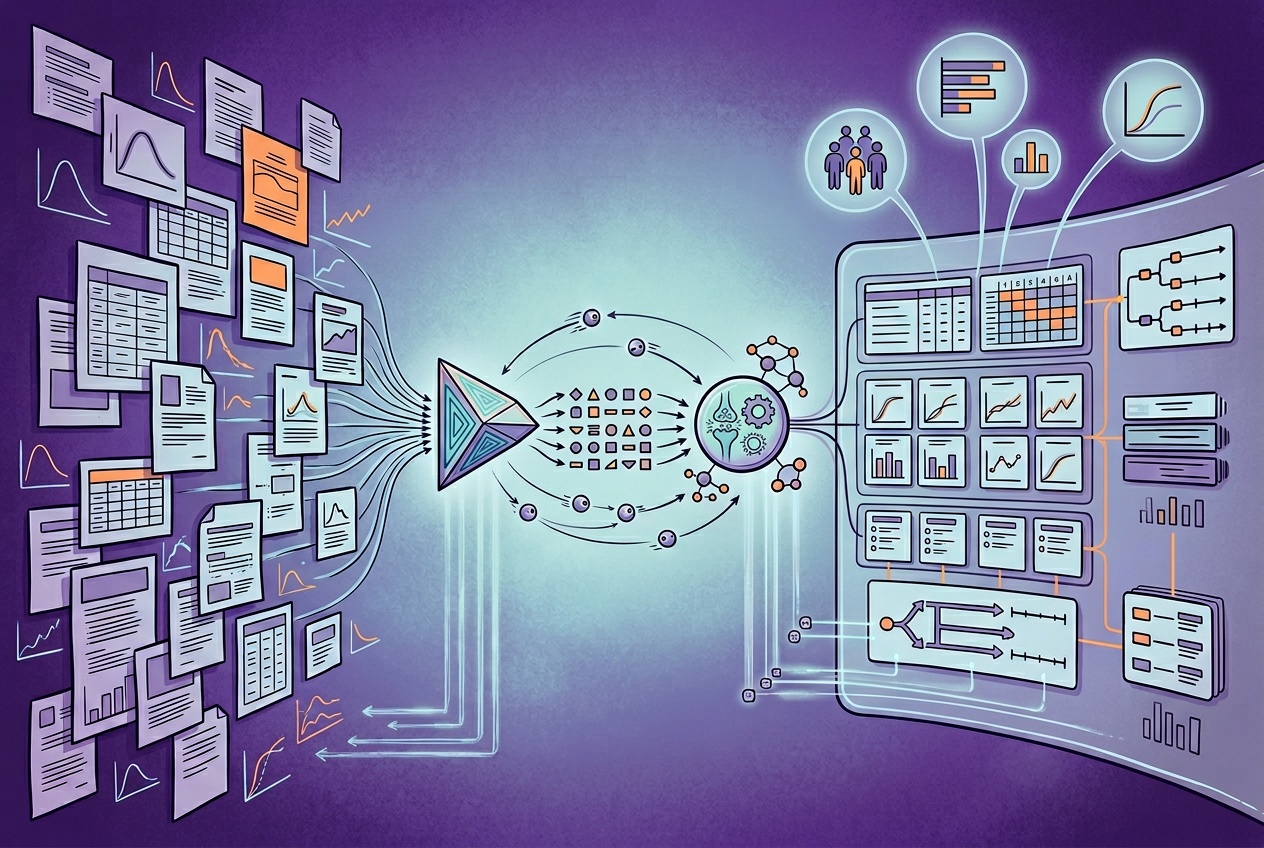
To bridge this gap, we has developed an agentic AI workflow that instantly transforms heterogeneous biomedical documents into structured data asset to design smarter, evidence-driven clinical trials, to evaluate early signs of efficacy by analyzing biomarkers, imaging readouts, and emerging digital measures.
To find the relationship between a drug’s systemic clearance and its physiological response requires navigating a maze of unstructured data. Imagine tracking a novel mechanism, like a "Brain Shuttle" biologic designed to cross the blood-brain barrier. The data you need lives in different places, generated at different times:
When clinical scientists, data scientists, and decision science teams try to pull this together, they hit a wall. Formats don't match, units are inconsistent, and data points are ambiguous or missing entirely. This reliance on manual curation creates disjointed workflows, introduces human error at scale, and ultimately leads to severe delays in generating critical R&D insights.
To solve this bottleneck, Elucidata built an agentic AI system designed specifically for the complexities of biomedical data.
Instead of relying on generic LLMs that are prone to hallucination, Polly Xtract combines specialized data modeling expertise with parallelized AI processing. You simply upload your heterogeneous sources -PDFs, tabular data, and even complex plots, and the system generates a custom, structured schema. It reliably extracts critical PK/PD parameters (half-life, clearance rates, biomarker changes over time), patient disease progression, and trial duration information.
Crucially, Polly Xtract maintains human-level accuracy at scale, providing >90% correct inline citations linking every extracted data point directly back to its source text or figure.
Once extracted, this harmonized data is exported into an Atlas environment. Here, your previously unstructured documents become a fully queryable, relational database, ready for programmatic access via SQL.
By automating the tedious curation process, your team transitions from data hunters to strategic thinkers.
Once the data is structured inside the Atlas environment, Polly Co-Scientist becomes your interface for exploration. Researchers no longer have to manually synthesize findings; they can directly ask focused questions against the harmonized clinical data.
You can trace how primary endpoints were defined in competitor trials for cleaner modeling of disease progression, or evaluate early signs of efficacy by analyzing biomarkers, imaging readouts, and emerging digital measures.
Instead of starting from scratch on every project, your team gains a persistent, shared knowledge base that acts as a force multiplier for the entire organization.
Implementing an agentic AI workflow fundamentally shifts how you evaluate risk and strategy:
If you are ready to accelerate your clinical development and eliminate the guesswork from your data workflows, connect with us to explore how we can help streamline your trial design process.

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



