.svg)
Automation Without Traceability: The Silent Risk in CDMO Workflows
Dharani Dadi

April 1, 2026
When we talk about automating CDMO workflows the obvious win is speed. Things that used to take hours now happen in minutes. No more manually copying numbers from spreadsheets into reports. No more waiting on someone to run a query. It feels like a huge upgrade, and honestly, it is.
But there's a version of this that goes wrong quietly. We build fast pipelines, the outputs look right, sponsors are happy, and then six months later an auditor asks: "Where did this yield number come from?" and nobody on the team can actually trace it back cleanly. The person who wrote the pipeline has moved on. The input file got overwritten. The logic was tweaked at some point but nobody logged when or why.
That's the problem with automation that skips traceability. We moved fast, but we built something we can't fully stand behind.
CDMOs operate in a uniquely accountable environment. We're not just running calculations for internal use. We're producing data that:
Every batch record, yield figure, analytical result, and stability data point is a potential audit touchpoint.
In a manual world, the paper trail was kind of built in by default. Someone signed the form, someone logged the entry, there was a clear human at each step who could be asked questions. When we automate, that natural accountability disappears unless we deliberately build it back in.
Automation doesn't eliminate the need to explain our data. It just means the explanation has to come from our system instead of a person's memory. And that's actually a higher bar. A person can walk an auditor through their reasoning in real time. A system needs to have logged it upfront.
Here's a situation that's more common than it should be:
Our pipeline pulls raw batch data every night, applies a yield calculation, and writes the final number into a report that goes to the sponsor. It runs reliably for months. Then one day a sponsor flags an anomaly in a number from six weeks ago. We go to investigate, but our pipeline didn't log which version of the input data it used that night. The intermediate calculation step just overwrote itself each run. The transformation logic was updated two months ago but nobody versioned it, so we don't know if the flagged output was produced by the old logic or the new one. The run log exists but it's a flat text file with timestamps and nothing else useful.
Now we're spending three days reconstructing something that should have been a ten-minute conversation. We're digging through git history, cross-referencing timestamps, trying to rebuild confidence in a number that was probably fine, but we can't prove it.
That's what missing traceability costs us. Not just during audits, but in the day-to-day work of operating a data pipeline in a regulated environment.
The good news is this doesn't have to mean slowing everything down or adding layers of manual sign-offs. Done right, traceability is built into the automation itself. It's just part of what the pipeline does.
Here's what that looks like concretely:
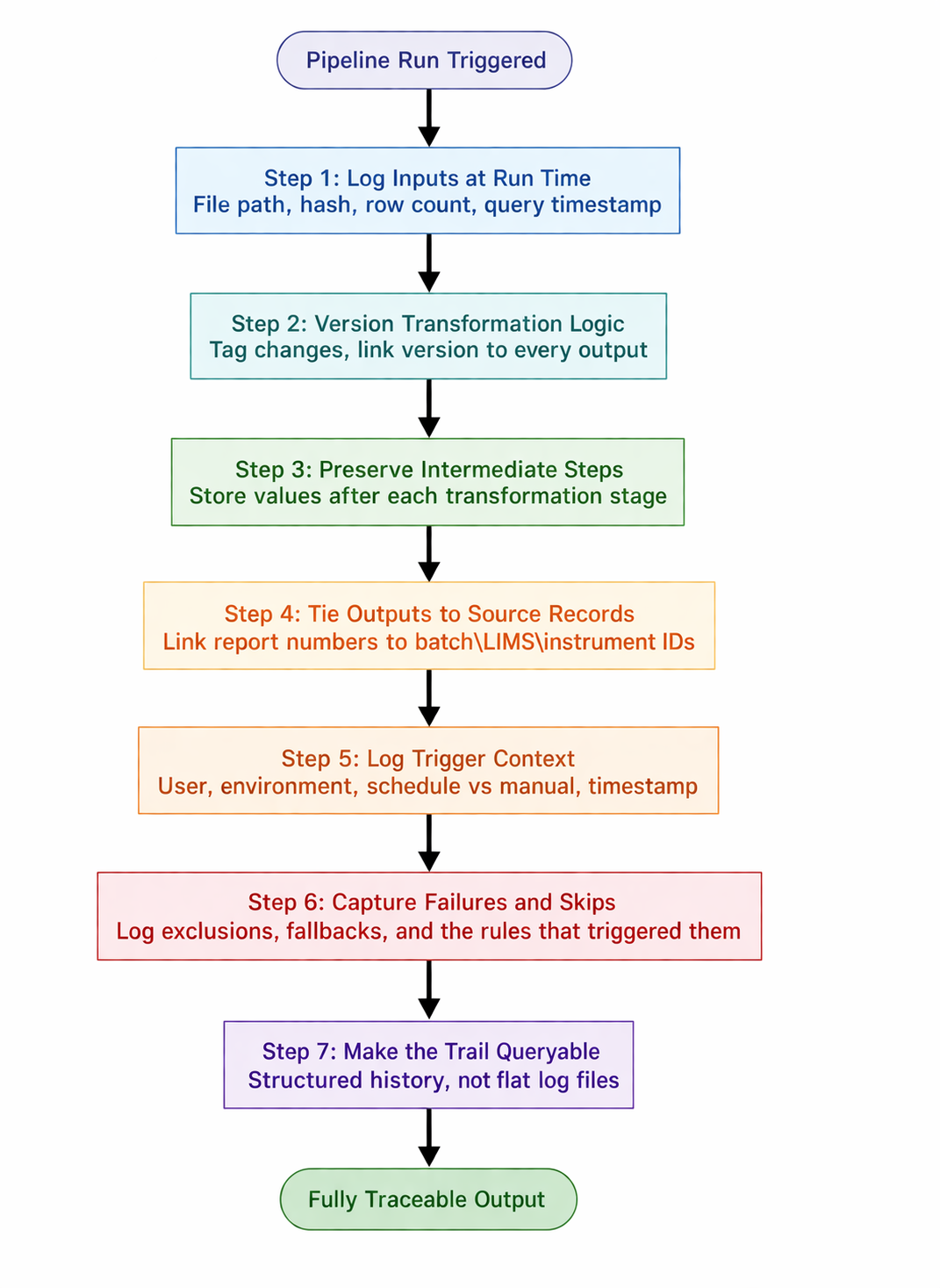
Every pipeline run should record exactly which version of the source data it used, not just "batch_data.csv" but the exact file path, timestamp, file hash, and row count at the time of ingestion. If our data comes from a database, log the query, the table version, and the timestamp of the pull. The goal is simple: if we need to rerun this exact pipeline three months from now and produce the same output, we should have everything we need to do it.
When our calculation logic changes (even a small formula tweak, even a unit conversion fix), that change needs to be versioned and the version needs to be linked to every output it produced. A yield number from last Tuesday should be able to tell us: "I was produced by pipeline v2.3.1, which was deployed on this date." Without that, we can't distinguish between a data problem and a logic problem when something looks off.
Don't just store the final output. Keep the intermediate calculated values that led to it: the raw inputs after cleaning, the values after each transformation, the pre-aggregation numbers before rollup. This is what lets us walk from raw instrument data to final report number step by step. When a sponsor asks "how did we get from this batch reading to this yield figure," we should be able to show them each step, not just the answer.
Every number that ends up in a report should be linkable to the specific batch record, instrument output, LIMS entry, or data submission it came from. This doesn't have to be complicated. Even just logging a source record ID alongside each output row is enough. That link is what makes the trail real. Without it, our report is a table of numbers with no provenance.
Automated doesn't mean anonymous. Each pipeline run should capture the full trigger context: was it a scheduled job or manually kicked off, which user or service account initiated it, which environment it ran in (dev, staging, prod), and the exact timestamp. In a regulated CDMO context, regulators care about who authorized an output, even if the output itself was machine-generated. "The system did it" is not an acceptable answer on its own.
Most logging only records what worked. But in a compliance context, a run that failed silently, skipped a record, or fell back to a default value is just as important to capture. If a batch was excluded from a calculation because a field was missing, that exclusion needs to be logged: what was excluded, why, and what rule triggered it. Auditors don't just check our outputs. They check whether our system handles edge cases consistently.
A flat log file nobody can search isn't a paper trail, it's just noise. Build the audit history into a structure where we can actually ask it questions: "show me every run that touched Batch XYZ," "what changed between the May report and the June report," "which pipeline version produced these outputs." If answering those questions requires someone to manually parse files or write a one-off script, the trail isn't really there yet.
Good traceability doesn't just protect us during audits. It makes the automation more useful day-to-day in ways that are easy to underestimate.
When something looks off in a report, we can pinpoint the cause in minutes instead of days. Was it bad input data, a logic change, or a one-off edge case? When a sponsor asks for clarification on a specific number, we have a clean, complete answer ready without scrambling. When we fix a bug in our calculation logic, we can immediately identify exactly which historical outputs were affected and which ones are clean. When we onboard a new team member, the pipeline's history explains itself.
In CDMO work, where data quality directly touches product quality and regulatory standing, that kind of visibility is genuinely valuable, not just as a safety net, but as an operational advantage.
Automation should make us faster and more transparent, not faster at the cost of transparency, because speed gets attention but traceability builds trust.

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



