.svg)
High Level Solution for Capacity Modelling CDMOs
Swastik Gowda L

March 16, 2026
CDMOs operate under a constant stream of evolving requirements from their Pharma partners. When a new RFP arrives for small molecule manufacturing, it often includes hundreds of pages of technical specifications and complex process details. Reviewing and acting on these documents both quickly and accurately is a significant challenge.
To address this, Elucidata partnered with a small molecule CDMO to streamline their capacity modeling workflow and enable faster, more competitive proposal generation. In this blog, we share the high-level solution architecture behind this workflow and how it improves accuracy, traceability, and throughput.
Capacity modeling requires inputs spanning chemical properties, manufacturing assumptions, contractual terms, timelines, and internal capacity constraints. In current workflows, these inputs are manually collected from multiple, disparate sources such as RFP documents, contracts, prior proposals, spreadsheets, and external references. This manual aggregation is time-consuming and introduces variability in how information is captured and interpreted.
As data moves across stages and between tools, traceability is gradually lost, making it difficult to determine where a specific value originated, whether it was inferred or explicitly stated, and who reviewed or approved it. This combination of manual collection and poor traceability makes validation difficult and weakens confidence in downstream capacity and cost estimates.
Spreadsheets remain the primary tool for storing data, performing calculations, and reviewing assumptions. While flexible, spreadsheets are not designed for complex, multi-stage capacity modeling involving validation rules, approvals, provenance tracking, and iterative refinement. As workflows grow in complexity, spreadsheet-based approaches become increasingly fragile, difficult to maintain, and hard to scale across teams or projects.
This reliance on spreadsheets also increases manual touchpoints, copying data between files, reconciling versions, and reapplying calculations, which slows throughput and makes the overall process unsuitable for complex and repeatable capacity modeling use cases.
Capacity and cost estimates are inherently sequential: outputs from one stage become inputs to the next. When errors occur during early extraction or estimation steps, they propagate through later calculations without being detected. Over multiple stages, small inaccuracies compound into materially unreliable capacity commitments, timelines, and cost projections.
Novel or proprietary chemicals are frequently not available in standard datasets. General-purpose LLMs may provide plausible-looking but incorrect chemical information based on pattern matching from previously digested data. External APIs can also return incomplete or inconsistent results.
Without a deterministic validation layer and explicit cross-source verification, chemical properties such as molecular formula, molecular weight, density, etc, become a major source of downstream error in capacity modeling.
Current capacity modeling workflows involve multiple manual handoffs between people and tools, leading to slow turnaround times. Reviews and corrections often require moving data across spreadsheets, documents, or email threads, making it difficult to process proposals efficiently.
Additionally, existing tools can be rigid and prescriptive, offering limited flexibility to adapt workflows or approval steps to organization-specific needs. This forces teams to work around the tool rather than with it, further reducing throughput and scalability.
We propose a configurable, AI-assisted, human-in-the-loop platform for capacity-first CDMO modeling. The platform is designed to automate repetitive tasks, reduce manual touchpoints, and improve throughput, while preserving transparency, validation, and human accountability at every critical step.
Rather than acting as a rigid product, the system will be built as a flexible solution that can be tailored to each organization’s capacity modeling processes, approval structures, and data standards, enabling teams to work more efficiently without compromising control or accuracy.
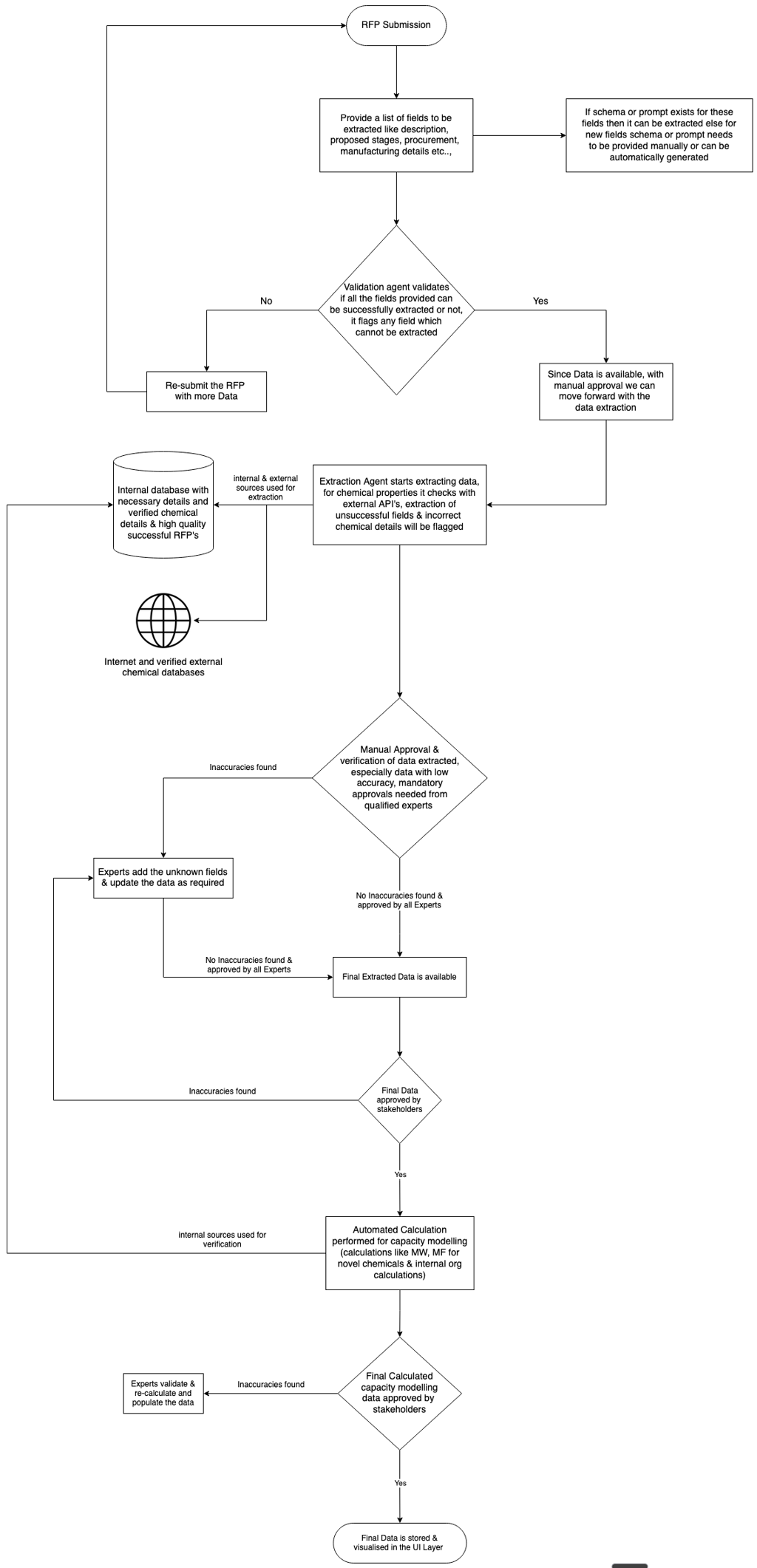
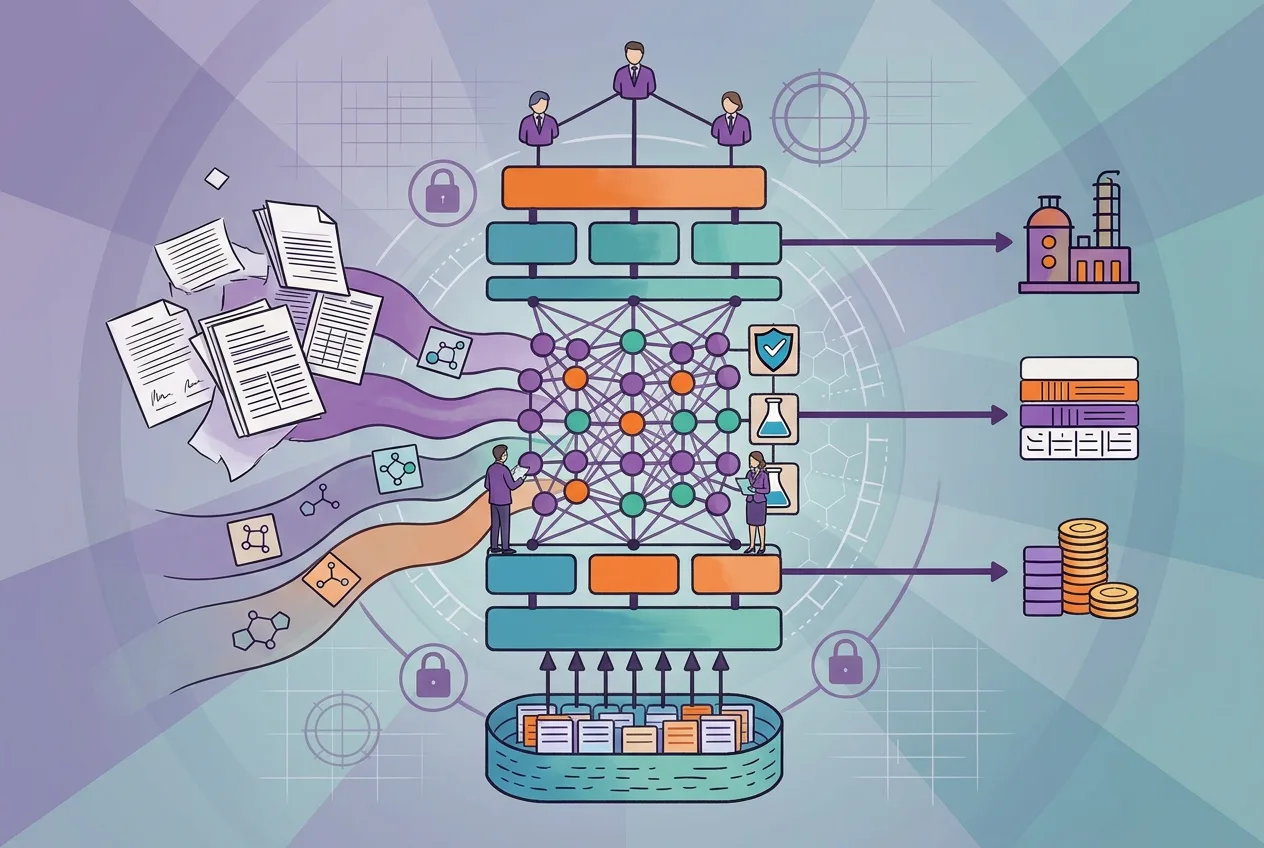
Users upload RFPs, technical documents, and contractual materials. The system extracts relevant information into a predefined structure covering areas such as descriptions, key attributes, requirements, proposed stages, procurement details, manufacturing details, yield assumptions, capacity and cost drivers, MSA terms, etc.
Each field is extracted using predefined prompts with high-quality examples, ensuring the output is consistently structured and easy to compare across proposals. Where appropriate, the AI can also add relevant details that are implied in the documents but not explicitly stated.
For every extracted field, the system explicitly indicates whether the value was AI-populated or manually entered, displays the source(s) used, and assigns a confidence or accuracy level. Fields with low confidence are flagged for attention and manual verification.
Certain sections, such as manufacturing details, capacity commitments, and contractual terms, require mandatory approval from qualified personnel before the workflow can proceed. At each step, users can interact with the AI to refine or correct extracted values.
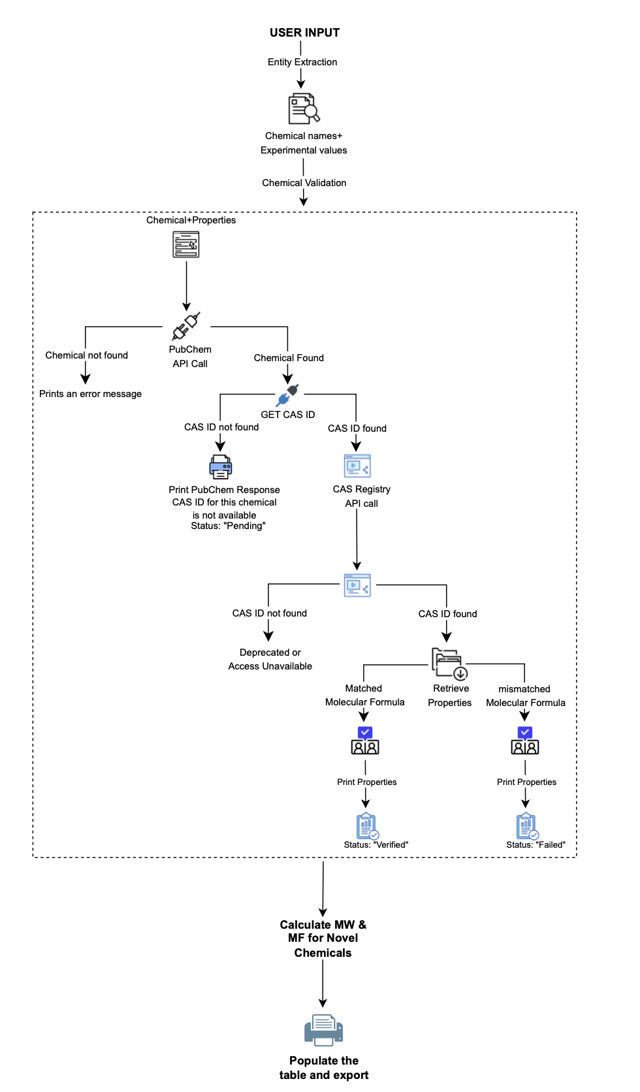
Chemical detail handling is implemented as a deterministic validation pipeline, rather than a free-form AI lookup process. The system initially queries authoritative sources such as PubChem to identify the chemical and retrieve associated identifiers and metadata. Since CAS identifiers obtained from PubChem may occasionally be incomplete or inaccurate, these identifiers are validated against additional trusted sources such as the CAS Registry, ChemicalBook, and Sigma-Aldrich.
Once a CAS identifier is confirmed, chemical properties are retrieved from multiple authoritative sources and cross-checked for consistency. Any discrepancies automatically trigger a mandatory manual verification step. If a property cannot be reliably established from verified sources, it is explicitly marked as unknown rather than inferred or approximated.
For novel or proprietary chemicals where external references are unavailable or incomplete, the system relies on fundamental chemical definitions. Molecular weight is calculated directly from the molecular formula, and derived properties (such as density, where applicable) are computed using validated calculation methods or flagged for expert review when assumptions are involved. No speculative values are introduced.
All verified and approved chemical information, whether externally sourced or internally derived, is stored in an internal, curated chemical database. This enables future proposals to reuse validated chemical data without repeating the full identification, validation, and review process, while maintaining full traceability and auditability.
Capacity modeling is treated as the primary objective, with cost modeling derived from validated capacity assumptions. Time and cost estimates are suggested based on a combination of verified internal datasets and historical high-quality RFPs.
The AI leverages knowledge of past successful proposals to populate realistic estimates, but final commitments require human approval. All assumptions remain visible, editable, and traceable.
Different models may be used for different tasks, such as extraction, chemical validation, and estimation. Users can compare outputs across models to assess quality. We continuously evaluate newer tools and models, promoting those that demonstrate improved accuracy or performance.
The platform tracks usage and performance metrics, including the number of RFPs processed, time saved per RFP, user correction frequency, and response times. User feedback and corrections are incorporated into the extraction and estimation logic over time.
Annual performance reports compare baseline performance with year-over-year improvements, enabling continuous optimization.
The solution includes a dedicated support channel (email, Slack, or Teams), a 24-hour response SLA for escalations and bug reports, and bi-weekly maintenance sprints for fixes and enhancements.
The platform can be designed to meet SOC 2 compliance requirements, building on prior experience delivering SOC 2–compliant systems. This includes implementing robust access controls, role-based permissions, comprehensive audit logging, and encryption of data at rest, along with secure key management & incident response management. The team also has prior experience in HIPAA-regulated environments and is capable of implementing systems that meet similar compliance and security expectations where required.

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



