.svg)
How Elucidata delivers Data-centric AI across the Drug Discovery lifecycle
Milan Gupta

December 4, 2025
.png)
The drug discovery process is long, expensive, and difficult. It takes over a decade and billions of dollars to bring a single new medicine to patients. A major reason for this difficulty is data.
Biological data is complex and messy. It comes from many different sources, in different formats, and is often locked away in separate systems (silos). Scientists spend more time cleaning and organizing this data than they do analyzing it.
This is where Elucidata comes in. Elucidata is a company that helps life sciences companies use their data more effectively. Our platform, Polly, uses a "data-centric" approach. This means we focus on improving the quality of the data itself, rather than just building more complex algorithms. By feeding high-quality, harmonized data into AI models, we help drug hunters make better decisions faster.
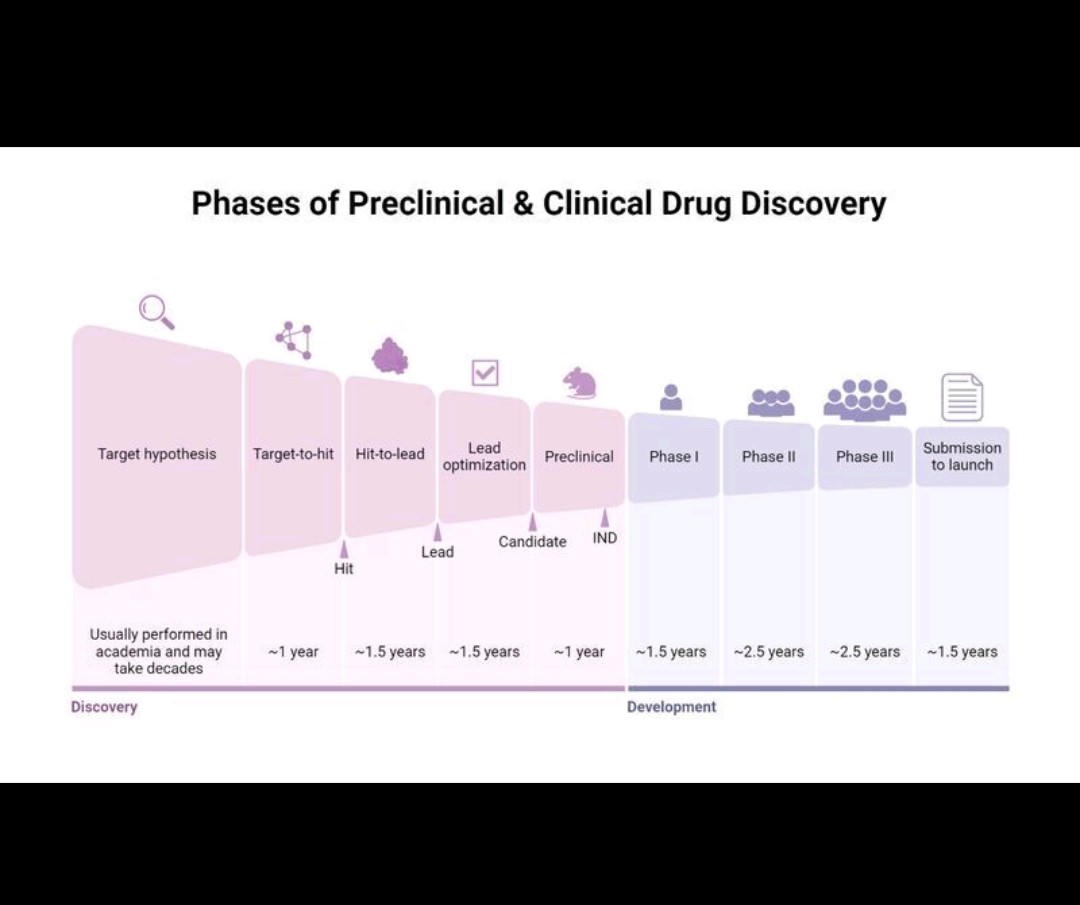
Here is a look at the drug discovery lifecycle and how Elucidata builds solutions at every stage.
The first step in drug discovery is finding a "target." A target is usually a protein or gene in the body that is causing a disease. If you can find a drug to affect this target, you might cure the disease.
The Challenge: To find a good target, scientists need to look at massive amounts of biological data (genomics, transcriptomics, etc.). This data often lives in public databases or internal company files, but it is unorganized. It is like trying to find a specific book in a library where all the books are thrown in a pile on the floor.
How Elucidata Works: Our platform, Polly, pulls data from public databases (like GEO) and a company's internal experiments. It then "harmonizes" this data. Harmonization means converting all the messy data into a single, standard format that computers can easily read.
The Data-Centric Value:
Once a target is found, scientists look for a molecule (a "lead") that can hit that target. They then optimize this molecule to make it more effective and safer. Before giving it to humans, they must test it in the lab (in vitro) and in animals (in vivo). This is the preclinical stage.
The Challenge: This stage generates huge amounts of data from different experiments. Scientists need to predict if a drug will be toxic (poisonous) before they spend money testing it in clinical trials. If data from past experiments is hard to find or compare, teams might repeat failed experiments or miss warning signs.
How Elucidata Works: Polly creates a central "Atlas" of data for the research team. It integrates data from safety assays, animal studies, and chemical structures. It allows scientists to run "virtual" experiments. For example, they can use AI to predict how a cell will react to a drug without actually using a physical sample, often called a "virtual cell."
The Data-Centric Value:
This is the most critical and expensive stage. The drug is tested in human volunteers in three phases (Phase I, II, and III) to prove it is safe and effective.
The Challenge: Clinical trials produce massive, diverse datasets. You have patient medical records (EHRs), genomic data from patient samples, and imaging data (like X-rays or CT scans). These come from different hospitals and labs, all using different terms and formats. Manually connecting a patient's genetic mutation to their response to the drug can take weeks of manual work.
How Elucidata Works: Elucidata automates the cleaning and linking of this data. We use Large Language Models (LLMs) and automated pipelines to standardize patient data. For instance, we can map different terms for the same disease into a single standard code (like OMOP or SNOMED).
The Data-Centric Value:
After successful trials, the company must submit all its data to regulators (like the FDA) for approval. Once the drug is on the market, they must continue to monitor its safety in the real world.
The Challenge: Regulators require data to be traceable, secure, and compliant. They need to know exactly where every data point came from. If data is messy or the "chain of custody" is unclear, approval can be delayed or denied.
How Elucidata Works: Polly ensures "audit-readiness." Because the data is processed through governed, automated pipelines, there is a clear digital trail of how raw data was turned into final results.
The Data-Centric Value:
The core philosophy behind Elucidata is simple: Better Data > Better Models.
In the past, many companies tried to solve problems by building complex AI models. But if you feed a super-smart AI "noisy" or incorrect data, it will give you bad answers. This is often called "Garbage In, Garbage Out."
Elucidata flips this. We focus on the "Data-Centric" approach. We believe that fixing the data—making sure it is labeled correctly, has no errors, and is consistent—is the most effective way to improve AI performance.
By providing AI-Ready data, we remove the biggest bottleneck in the drug discovery lifecycle. Scientists stop being "data janitors" and start being explorers again.
The drug discovery lifecycle is a relay race where information must be passed smoothly from one stage to the next. When data is siloed or messy, the baton gets dropped.
Elucidata ensures the baton is passed securely and quickly. From finding the first target to monitoring a drug on the market, our data-centric platform, Polly, connects the dots. We turn chaos into clarity, helping life sciences companies save millions of dollars and, most importantly, get life-saving medicines to patients faster.

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



