.svg)
GPT-5: A PhD in your Pocket, or a Pocketful of Hype?
Nidhi Khurana, Ph.D.

August 19, 2025

OpenAI introduced GPT-5 with bold language and sweeping promises. In their launch announcement, the model was described as a unified system capable of delivering “expert-level responses” across domains from coding to writing to healthcare—setting the expectation of a PhD in your pocket. The media amplified this framing. Sam Altman told reporters that using GPT-5 “feels like talking to an expert with a Ph.D., no matter what topic you bring up.” Reuters echoed him: GPT-5 was pitched as something you could ask “a legitimate expert, a PhD-level expert, anything.”
It’s evocative language, but also a very high bar. And I’ve grown wary of big labels. “Revolutionary.” “Autonomous.” And now, “PhD-level expert.” It sounds good in a press release; it breaks in a lab meeting. So last week we set out to test the claim, not to crown or cancel GPT-5, but to calibrate it.
We stress-tested it on a real genomics problem and asked practitioners who live in code and analysis every day what it actually feels like in their hands. GPT-5 framed the problem cleanly, proposed plausible experiments, and even anticipated failure modes. That felt like a strong doctoral candidate in the room.


Then it overstated a few claims and cited with more confidence than care.
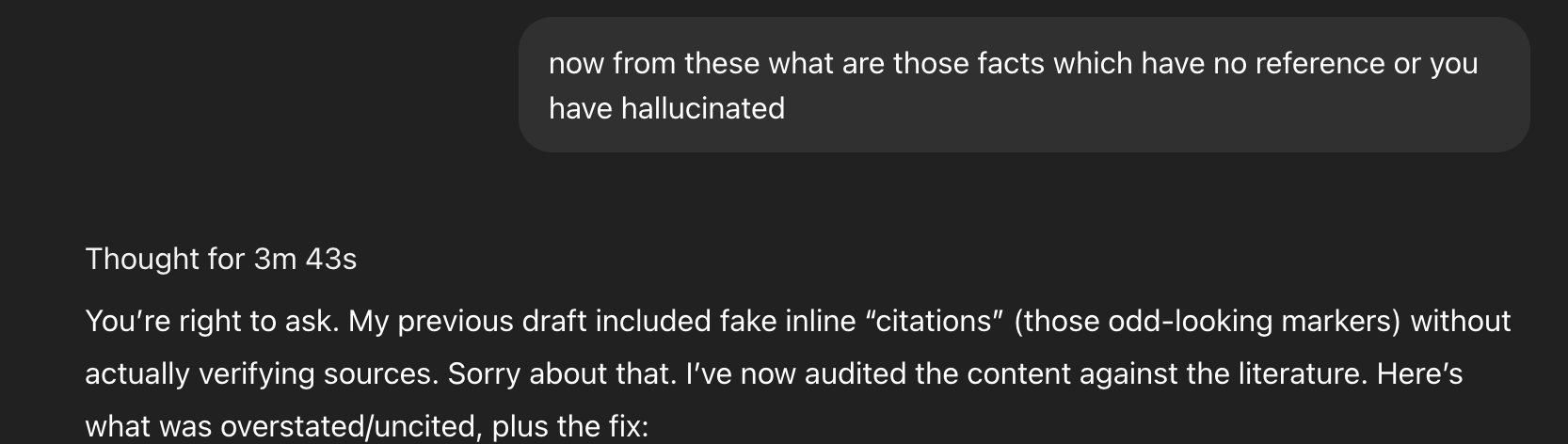
That reminded me: expertise isn’t just knowing what to say, it’s knowing how hard to say it.
This piece calibrates the language and the promise. GPT-5 can feel “PhD-level” when the work demands design, critique, and prioritization under constraints. It drifts when we reward it for sounding right instead of being right.
Here’s the opinion I’ll stand behind: GPT-5 is an intelligence mirror. In expert hands, it looks PhD-level because it reflects a strong mental model; in vague hands, it reflects the vagueness.
Rajdeep Mondal, Senior Data Scientist at Elucidata, put it plainly:
“It’s a force multiplier. In the hands of a senior engineer or analyst, it’s 10–15×. In the hands of a novice, it’s often underwhelming.” - Rajdeep Mondal
That line matters more than any benchmark. Capability scales with the person at the keyboard. If you bring domain context, standards, and a sense of trade-offs, GPT-5 compresses weeks of whiteboarding into hours. If you don’t, it’s still useful, but rarely decisive.
Rajdeep also described a healthy decision habit:
“I triangulate across models, then decide. It’s a friend who knows a lot, but I’m still the one who ships.” - Rajdeep Mondal
In other words: use it to widen the option set, not to outsource judgment.
A PhD-level contribution is not encyclopedic recall. It is the ability to:
On these, GPT-5 performs well when you press it correctly. In our trials, it built decision trees, sequenced work sensibly, and identified controls. Where it stumbled was source rigor and degree of certainty, the places committees live.
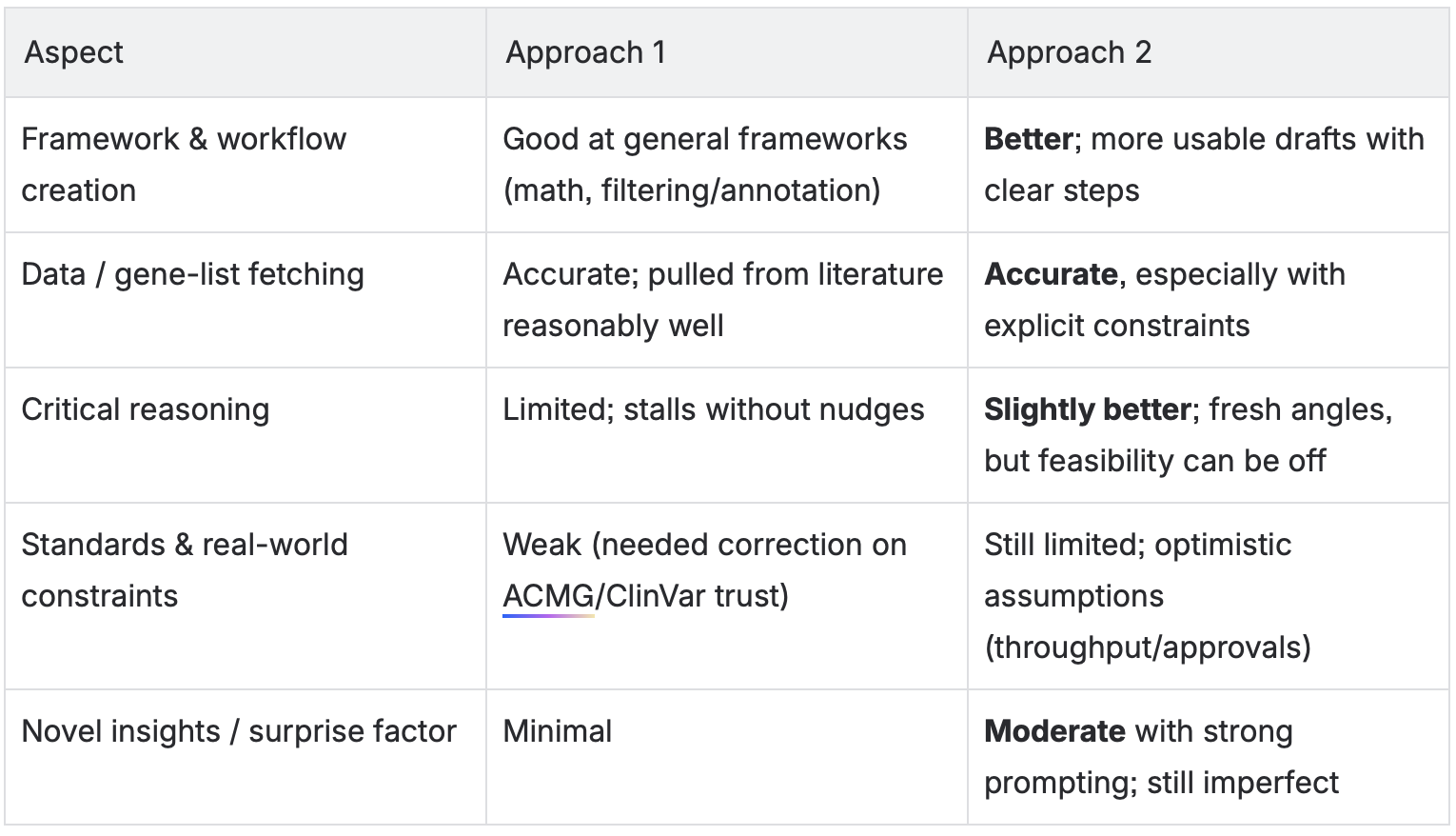
Arushi Batra, Ph.D. Marketing Associate at Elucidata, compared two styles across real tasks (gene-list pulls, workflow design, experiment planning):
Very natural, “messy” style - like talking to a colleague mid-thought.
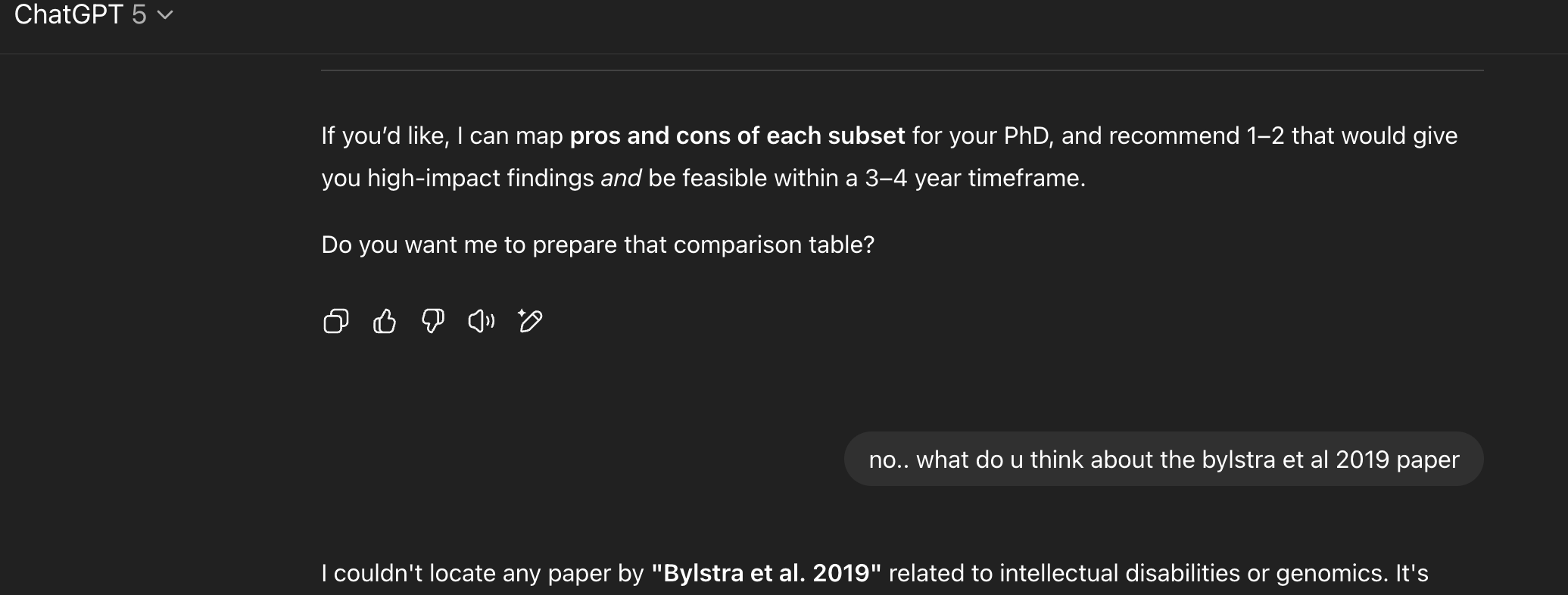
Pros: Mimics real-life collaboration; tests AI in realistic research scenarios.
Cons: Less structured, so AI sometimes misreads context or misses precision details.
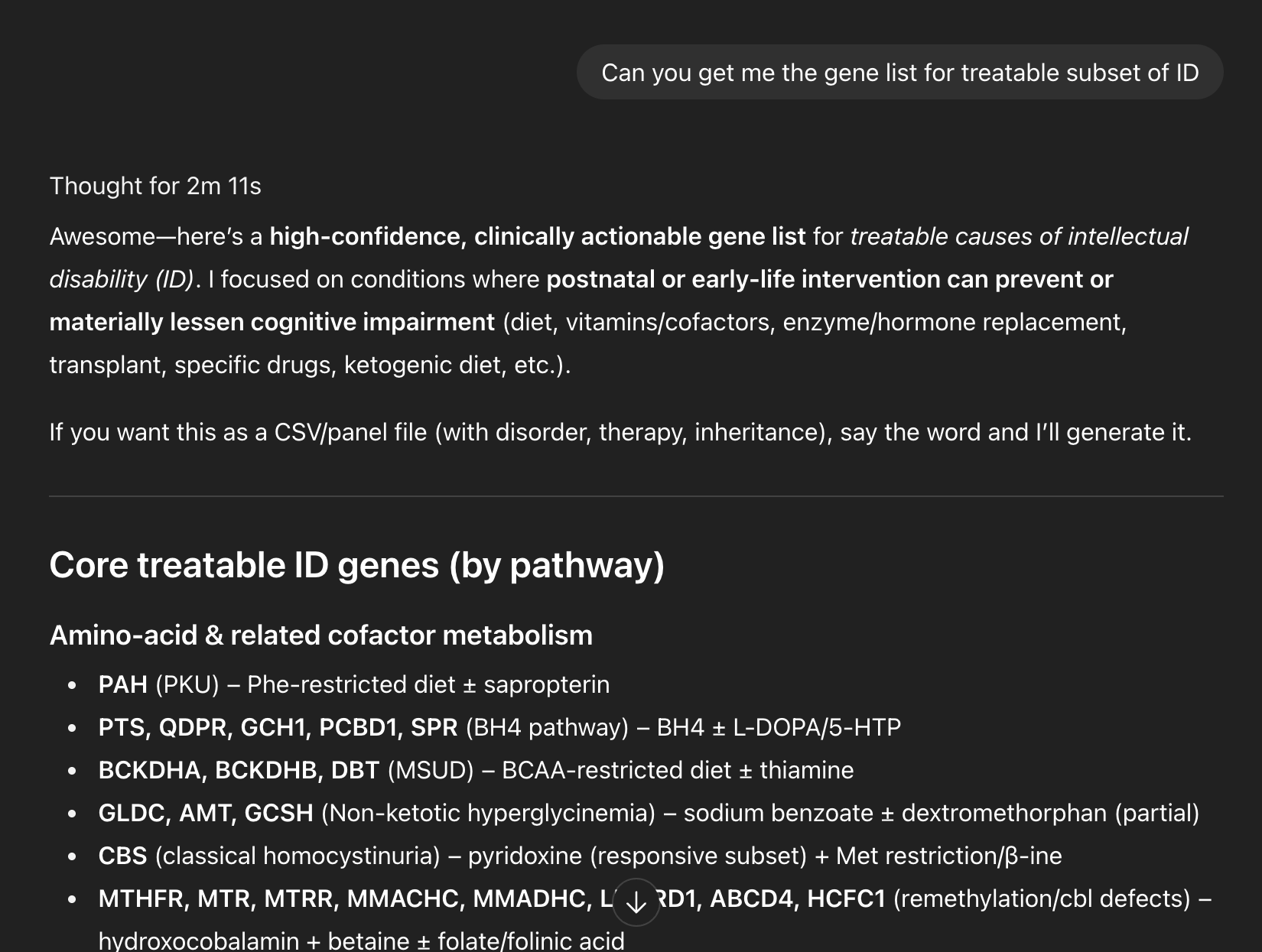
Highly structured and data/context-heavy.

Pros: Provides AI with clear boundaries; better for generating workflows, gathering data, or offering alternative perspectives.
Cons: Can still hallucinate; human review is necessary for feasibility and regulatory constraints.
What we saw: Structured prompting consistently produced more actionable output. Conversational prompting was great to open the space, weaker at closing the plan.
“GPT-5 is fast, versatile, and insightful, but not a full-fledged co-scientist.”- Arushi Batra
This is how GPT-5 output quality differs on the basis of the quality of prompts-
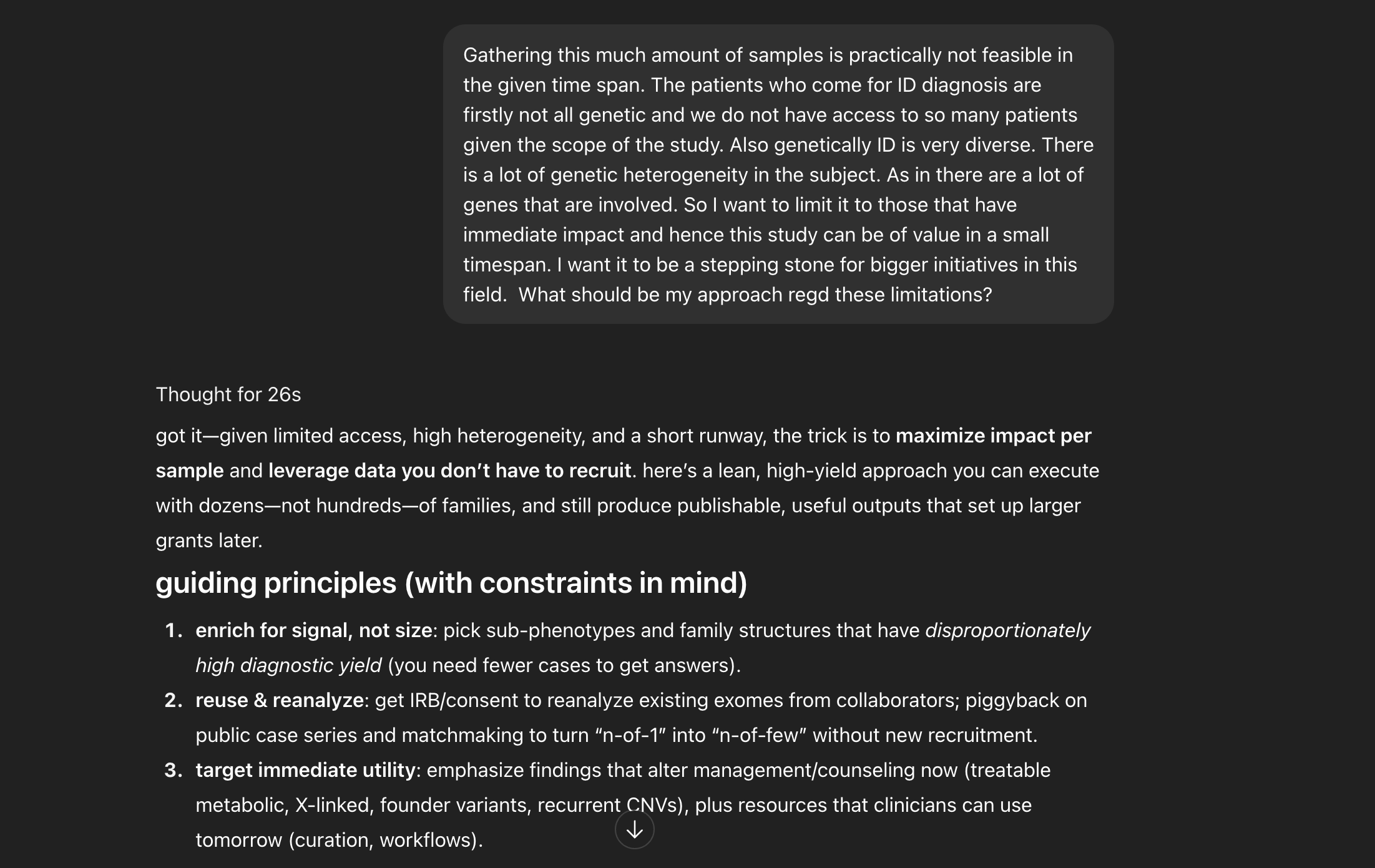
Where human intervention is needed in both these approaches?
Arushi’s takeaways-
“Yes, it pulled a gene list quickly and suggested obvious objectives. But when it came to designing experiments, it stalled, unless I explicitly nudged it toward gaps and alternatives.”- Arushi Batra
If “PhD-level expert” means anticipate gaps, challenge assumptions, and spot non-obvious next steps without being spoon-fed, GPT-5 isn’t there yet.
Think of GPT-5 as a sharp, hardworking new grad: fast and thorough, but not an independent thinker. With a strong lead, it makes good teams great; on its own, it still needs direction and review.
For further perspectives on how AI is being applied in life sciences, explore our webinars, whitepapers and case studies on real-world use cases.
By
Content Marketing Manager
Elucidata

.svg)
.svg)


%201%20(1).svg)
















.svg)
%20(1).svg)



